
An Intelligent Speech Recognition Framework Using Hidden Markov Models and Actor–Critic Deep Reinforcement Learning for Low-Resource African Languages
DOI:
https://doi.org/10.70882/josrar.2026.v3i3.151Keywords:
Automatic Speech Recognition (ASR), Hidden Markov Model (HMM), Actor–Critic Deep Reinforcement Learning, Deep Deterministic Policy Gradient (DDPG), Mel-Frequency Cepstral Coefficients (MFCC)Abstract
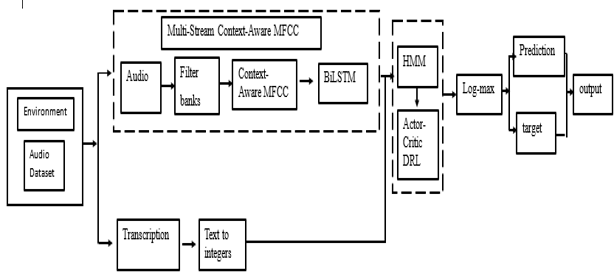
ASR also plays a crucial role in assistive technologies for individuals with disabilities by enabling them to manage their surroundings more effectively through dialing phone numbers, operating light switches, and controlling home appliances, thereby contributing to the development of smart home systems. This study extracts features from isolated speech using Mel-Frequency Cepstral Coefficients (MFCC) and Bidirectional Long Short-Term Memory (BiLSTM) networks to ensure speaker invariance and enhance feature localization. Deep learning techniques were employed to explicitly normalize speech spectral features. Numerous pattern recognition and regression tasks have demonstrated the effectiveness of LSTM-based architectures. The novelty of this study lies in the integrating a hybrid MFCC–DNN–HMM framework to achieve high speech recognition accuracy for isolated words. The model achieved an accuracy of 0.945 (94.5%), indicating that it correctly classified the majority of instances. The precision obtained was 0.901, meaning that 90.1% of the instances identified as positive were correctly classified. The recall rate was 0.92, indicating that 92% of the actual positive instances were successfully detected by the system. The F1-score was 0.909, reflecting a balanced measure of precision and recall.
References
Aljinu Khadar, M., Rahman, A., & Suresh, P. (2023). Gaussian mixture model–universal background model I-vector approach for speaker verification in noisy environments. International Journal of Speech Technology, 26(3), 455–468.
Babu, R., Kumar, S., & Reddy, V. (2023). A comprehensive classification of speech recognition approaches: Pattern recognition, acoustic-phonetic, and artificial intelligence methods. Journal of Signal Processing Systems, 95(4), 601–615.
Barkani, A., El Moutaouakil, K., & El Mohajir, M. (2023). Amazigh automatic speech recognition using the Kaldi toolkit. Speech Communication, 152, 45–57.
Biswas, T., Roy, S., & Chatterjee, A. (2023). Spoken language identification using MFCC features and machine learning classifiers. Expert Systems with Applications, 221, 119765.
Fadhel, M., & Mohammed, H. (2023). Classification and evaluation of automatic speech recognition systems. International Journal of Computer Applications, 185(12), 25–34.
Hazmoune, Y., Benyettou, M., & Ouni, K. (2024). An ensemble hidden Markov model approach for robust speech recognition. IEEE Access, 12, 33421–33435.
Isaac, S., Haruna, K., Ahmad, M. A., & Mustapha, R. (2023). Deep reinforcement learning with hidden Markov model for speech recognition. Journal of Technology and Innovation, 3(1), 1-5.
Kanke, S., Patil, A., & Joshi, R. (2023). Marathi speech recognition using language-specific acoustic modeling techniques. Procedia Computer Science, 218, 987–996.
Manideep, K., & Mohana, R. (2023). Voice recognition using hybrid Gaussian mixture model and hidden Markov model. International Journal of Intelligent Systems and Applications, 15(2), 112–124.
Mishra, D., Verma, P., & Singh, A. (2024). Comparative analysis of machine learning techniques for automatic speech recognition. Multimedia Tools and Applications, 83(5), 14321–14345.
Moondra, A., Jain, S., & Kulkarni, P. (2023). Modified MFCC-GMM approach for speaker recognition under degraded speech conditions. Applied Acoustics, 206, 109251.
Nugroho, H., Prasetyo, E., & Wibowo, S. (2023). Multi-accent speaker detection using normalized MFCC and neural networks. Neural Computing and Applications, 35(14), 10523–10536.
Ouisaadane, H., El Hannani, A., & Boulaknadel, S. (2024). Moroccan dialect speech recognition using PocketSphinx in noisy environments. Speech Communication, 160, 78–90.
Pavithran, P., & Sherly, E. (2024). Hidden Markov model-based automatic speech recognition system for individuals with hearing impairment. Biomedical Signal Processing and Control, 89, 105432.
Prabhu, S., & Jayasri, V. (2024). Hidden Markov model-based speech recognition system for vending machine applications. International Journal of Embedded Systems, 17(1), 65–76.
Ramadan, Z., & Bitmead, R. (2022). Gaussian mixture models and maximum likelihood estimation for speech recognition systems. Signal Processing, 196, 108511.
Sallagundla, S., Rao, P., & Krishna, M. (2023). Voice-enabled form filling system using hidden Markov models. Journal of Ambient Intelligence and Humanized Computing, 14(8), 10923–10935.
Santos, L., Pereira, J., & Almeida, F. (2023). Hybrid HMM-CNN architecture for improved automatic speech recognition. IEEE Access, 11, 91234–91248.
Shafieian, R. (2023). Persian speech recognition using hidden Markov models. International Journal of Speech Technology, 26(2), 233–245.
Sudarshan, R., Karthik, S., & Menon, V. (2023). Context-aware automatic speech recognition using semantic processing. Artificial Intelligence Review, 56(6), 4891–4910.
Thimmaraja, Y., Ramesh, H., & Kumar, N. (2024). Real-time Kannada continuous speech recognition using hidden Markov models. International Journal of Speech Technology, 27(1), 101–115.
Tsai, C. H., & Wang, Y. T. (2023). Hardware-efficient Gaussian mixture model-based speaker verification system using MFCC features. IEEE Transactions on Circuits and Systems II: Express Briefs, 70(9), 3150–3154.
Wirdiani, A., Santoso, D., & Prabowo, R. (2024). MFCC-CNN with online triplet mining for robust speaker recognition. Expert Systems with Applications, 235, 120123.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Samson Isaac, Muhammad Aminu Ahmad, Peter Ayuba (Author)

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
- Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- NonCommercial — You may not use the material for commercial purposes.
- No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.

